Here I just want to say that I am struck by the parallels that exist between the activities of developer testing and operations monitoring. It's not a new idea by any means, but it's been growing on me recently.
Test-infected vs. monitoring-infected
Good developers are test-infected. It doesn't matter too much whether they write tests before or after writing their code -- what matters is that they do write those tests as soon as possible, and that they don't consider their code 'done' until it has a comprehensive suite of tests. And of course test-infected developers are addicted to watching those dots in the output of their favorite test runner.
Good ops engineers are monitoring-infected. They don't consider their infrastructure build-out 'done' until it has a comprehensive suite of monitoring checks, notifications and alerting rules, and also one or more dashboard-type systems that help them visualize the status of the resources in the infrastructure.
Adding tests vs. adding monitoring checks
Whenever a bug is found, a good developer will add a unit test for it. It serves as a proof that the bug is now fixed, and also as a regression test for that bug.
Whenever something unexpectedly breaks within the systems infrastructure, a good ops engineer will add a monitoring check for it, and if possible a graph showing metrics related to the resource that broke. This ensures that alerts will go out in a timely manner next time things break, and that correlations can be made by looking at the metrics graphs for the various resources involved.
Ignoring broken tests vs. ignoring monitoring alerts
When a test starts failing, you can either fix it so that the bar goes green, or you can ignore it. Similarly, if a monitoring alert goes off, you can either fix the underlying issue, or you can ignore it by telling yourself it's not really critical.
The problem with ignoring broken tests and monitoring alerts is that this attitude leads slowly but surely to the Broken Window Syndrome. You train yourself to ignore issues that sooner or later will become critical (it's a matter of when, not if).
A good developer will make sure there are no broken tests in their Continuous Integration system, and a good ops engineer will make sure all alerts are accounted for and the underlying issues fixed.
Improving test coverage vs. improving monitoring coverage
Although 100% test coverage is not sufficient for your code to be bug-free, still, having something around 80-90% code coverage is a good measure that you as a developer are disciplined in writing those tests. This makes you sleep better at night and gives you pride in producing quality code.
For ops engineers, sleeping better at night is definitely directly proportional to the quantity and quality of the monitors that are in place for their infrastructure. The more monitors, the better the chances that issues are caught early and fixed before they escalate into the dreaded 2 AM pager alert.
Measure and graph everything
The more dashboards you have as a devops, the better insight you have into how your infrastructure behaves, from both a code and an operational point of view. I am inspired in this area by the work that's done at Etsy, where they are graphing every interesting metric they can think of (see their 'Measure Anything, Measure Everything' blog post).
As a developer, you want to see your code coverage graphs showing decent values, close to that mythical 100%. As an ops engineer, you want to see uptime graphs that are close to the mythical 5 9's.
But maybe even more importantly, you want insight into metrics that tie directly into your business. At Evite, processing messages and sending email reliably is our bread and butter, so we track those processes closely and we have dashboards for metrics related to them. Spikes, either up or down, are investigated quickly.
Here are some examples of the dashboards we have. For now these use homegrown data collection tools and the Google Visualization API, but we're looking into using Graphite soon.
Outgoing email messages in the last hour (spiking at close to 100 messages/second):


Percentage of errors across some of our servers:
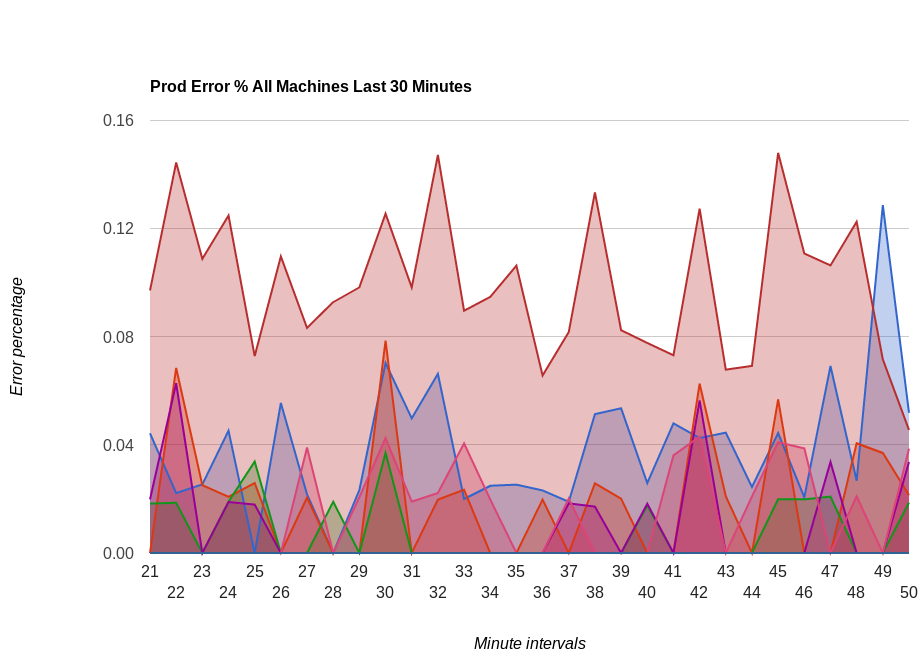
Associated with these metrics we have Nagios alerts that fire when certain thresholds are being met. This combination allows our devops team to sleep better at night.
9 comments:
What do you use to get those graphs?
I also found it interesting that you use percentages for total errors. How do you count those?
Hi Heikki
We use something similar to what I described here: http://agiletesting.blogspot.com/2010/07/tracking-and-visualizing-mail-logs-with.html
(although we keep some of this data in MySQL, not necessarily MongoDB)
For percentages, we keep track of the total # of requests from the nginx logs, and we compute the percentages of different types of HTTP error codes.
Great post!
Following a discussion with some other DevOps-minded folks I think I believe that devers are just as much responsible for being monitoring-infected as the ops folks.
Coming from an embedded, realtime background I know there's a need to create the software hooks that will enable "soft-level" monitoring points. In the hardware world, these points are designed into the the schematics as "test points", to enable monitoring and troubleshooting.
Unfortunately, I don't think architectures are as in-tune with that notion as the developers are. In the light of DevOps do you think ops folks working hand-in-hand with the architects and developers early in the lifecycles can help drive your points further?
Hi Grig, this is great stuff, it completely resonates with my experience. I've been a system engineer for most of my career, increasingly doing more development until I switched full time to sw dev in an environment that practised Agile. In the process I came to realize the exact parallel you describe in this post. Last month I gave a talk at FOSDEM on this very topic, if you were interested you can look at the slides and the video of the talk here. I'd love to talk more about this topic so feel free to reach out to me @spikelab. Thanks.
Kit -- thanks for the comments. I think the 'infection' needs to go both ways, i.e devs need to be more monitoring-infected, and ops need to be more testing-infected. This is the promise of Devops after all...But you are right, there needs to be a close dialog early in the game, and both devs and ops need to be closely involved in the architecture design of both the code and the infrastructure. I've seen it happen, so it's definitely possible!
Spike -- thanks for the pointer to your slides. Great presentation, and indeed we're on the same wavelength when it comes to testing and monitoring. I particularly liked your code example showing the various /mon handlers. I think all self-respecting apps should have that!
Spike -- thanks for the pointer to your slides. Great presentation, and indeed we're on the same wavelength when it comes to testing and monitoring. I particularly liked your code example showing the various /mon handlers. I think all self-respecting apps should have that!
Have you looked into detecting abnormal variation?
Jason -- not yet, but it's on my big and getting bigger TODO list ;-)
Post a Comment