A recent issue that surfaced on the selenium-users mailing list was related to running Selenium in "Driven Mode" (soon to be dubbed Remote Control or RC mode) by using the Twisted-based Selenium server on Linux. Normand Savard had followed my initial instructions, but was getting CGI "premature end of script" errors. I tried to follow my own instructions using the latest Selenium code and I got the same error. I managed to get it to work, so I'm posting the steps I went through to solve it.
My setup was a Linux box running Ubuntu Breezy with Python 2.4.2.
1. Download and install Twisted version 1.3 (this is important, because things have been known not to work so well with Twisted 2.x). Old versions of Twisted, including 1.3, can be downloaded from here.
2. Check out the Selenium source code:
svn co http://svn.openqa.org/svn/selenium/trunk selenium
3. Let's assume you checked out the code in ~/proj/selenium. You need to copy the contents of ~/proj/selenium/code/javascript (the contents, not that directory itself) into the ~/proj/selenium/code/python/twisted/src/selenium/selenium_driver directory.
4. Cd into ~/proj/selenium/code/python/twisted/src/selenium/cgi-bin and do:
# dos2unix nph-proxy.cgi
# chmod +x nph-proxy.cgi
Now edit nph-proxy.cgi and replace the path to perl in the first line from the Windows-specific path that's in there by default, to the real path to perl on your Linux box (in my case it was /usr/bin/perl).
5. Cd into ~/proj/selenium/code/python/twisted/src/selenium and start the Selenium Twisted server:
# python selenium_server.py
To verify that the server is up and running, open this URL in a browser:
http://localhost:8080/selenium-driver/SeleneseRunner.html
You should see the Selenium Functional Test Runner page at this point. You can then close the browser.
6. Cd into ~/proj/selenium/code/python/twisted/src/examples and edit the file google-test-xmlrpc.py. Replace the line:
os.system('start run_firefox.bat')
with:
os.system("/usr/bin/firefox http://localhost:8080/selenium-driver/SeleneseRunner
.html &")
(you might need to replace /usr/bin/firefox with the actual path to firefox on your Linux box)
7. Run
# python google-test-xmlrpc.py
At this point, a Firefox window will be automatically opened, the browser will connect to the SeleneseRunner.html page and will execute the test commands specified in the google-test-xmlrpc.py script. You should see the bottom frame of the SeleneseRunner.html page open the Google home page, then enter a search phrase and run the search.
That's it. You're now the proud owner of a Driven Selenium installation.
For instructions on running the Selenium Twisted server on Windows, see this post. For resolutions of other various issues that people were faced with, see this other post.
Wednesday, March 29, 2006
Wednesday, March 22, 2006
Bunch O'Links on agile/testing topics
Titus suggested I post some of the links I keep sending him, so here they are:
Darren Hobbs talks about "Why a 20 minute build is 18 minutes too long". The build in question included acceptance tests. His conclusion is that I/O is the enemy. My take on it is that a continuous build system should run all the unit tests, plus a subset of acceptance tests that are known to run fast. The other acceptance tests, especially the ones that do a lot of I/O, can be run more leisurely, once every X hours.
Michael Hunter, aka The Braidy Tester, posts his impressions on Uncle Bob's SDWest talk on Agility and Architecture. I particularly enjoyed this point: "The first, most important part of making code flexible is to surround it with tests."
Tim Ottinger (from ButUncleBob's crew) blogs on his experience with Testing Hypothetically. It's all about seeing the big picture when writing acceptance tests, and not being bogged down in the implementation-specific details that are best left to the realm of unit testing.
Brian Marick tells us to pay attention when finishing a story. Is the system better off (more malleability is what Brian is looking for) now that the story is done?
Roy Osherove posted the first article in what I hope is a long series on "Achieving and recognizing testable software designs". He discusses a problem that I also raised in the Agile Testing tutorial at PyCon: writing good unit tests is hard. But thinking about making your system testable will go a long way toward increasing the quality of your system. And Roy proceeds with practical recipes on how to achieve this goal. Great article.
While I'm mentioning unit testing articles, here's another good one from Noel Llopis's Games from Within blog: "Making better games with TDD". I haven't seen too many articles on developing games in a TDD manner, and this one really stands out. I particularly enjoyed their discussion of when and when not to use mock objects. A lot of lessons learned in there, a lot of food for thought.
Andrew Glover writes about FIT in his IBM developerWorks article "Resolve to get FIT". Nothing too earth-shattering, but it's always nice -- at least for me -- to see tutorials/howtos on using FIT/FitNesse, since it's an area I feel it's under-represented in the testing literature (but some of us are on a mission to change that :-)
Finally (for now), via Keith Ray, here are Agile Development Conversations in the form of podcasts.
I'm thinking about periodically posting stuff like this. Of course, I could just post my del.icio.us bookmarks, but going through the articles and commenting on them a bit helps me in committing the highlights to memory.
Darren Hobbs talks about "Why a 20 minute build is 18 minutes too long". The build in question included acceptance tests. His conclusion is that I/O is the enemy. My take on it is that a continuous build system should run all the unit tests, plus a subset of acceptance tests that are known to run fast. The other acceptance tests, especially the ones that do a lot of I/O, can be run more leisurely, once every X hours.
Michael Hunter, aka The Braidy Tester, posts his impressions on Uncle Bob's SDWest talk on Agility and Architecture. I particularly enjoyed this point: "The first, most important part of making code flexible is to surround it with tests."
Tim Ottinger (from ButUncleBob's crew) blogs on his experience with Testing Hypothetically. It's all about seeing the big picture when writing acceptance tests, and not being bogged down in the implementation-specific details that are best left to the realm of unit testing.
Brian Marick tells us to pay attention when finishing a story. Is the system better off (more malleability is what Brian is looking for) now that the story is done?
Roy Osherove posted the first article in what I hope is a long series on "Achieving and recognizing testable software designs". He discusses a problem that I also raised in the Agile Testing tutorial at PyCon: writing good unit tests is hard. But thinking about making your system testable will go a long way toward increasing the quality of your system. And Roy proceeds with practical recipes on how to achieve this goal. Great article.
While I'm mentioning unit testing articles, here's another good one from Noel Llopis's Games from Within blog: "Making better games with TDD". I haven't seen too many articles on developing games in a TDD manner, and this one really stands out. I particularly enjoyed their discussion of when and when not to use mock objects. A lot of lessons learned in there, a lot of food for thought.
Andrew Glover writes about FIT in his IBM developerWorks article "Resolve to get FIT". Nothing too earth-shattering, but it's always nice -- at least for me -- to see tutorials/howtos on using FIT/FitNesse, since it's an area I feel it's under-represented in the testing literature (but some of us are on a mission to change that :-)
Finally (for now), via Keith Ray, here are Agile Development Conversations in the form of podcasts.
I'm thinking about periodically posting stuff like this. Of course, I could just post my del.icio.us bookmarks, but going through the articles and commenting on them a bit helps me in committing the highlights to memory.
Tuesday, March 21, 2006
Ajax testing with Selenium using waitForCondition
An often-asked question on the selenium-users mailing list is how to test Ajax-specific functionality with Selenium. The problem with Ajax testing is that the HTML page under test is modified asynchronously, so a plain Selenium assert or verify command might very well fail because the element being tested has not been created yet by the Ajax call. A quick-and-dirty solution is to put a pause command before the assert, but this is error-prone, since the pause might be not sufficient on a slow machine, while being unnecessarily slow on a faster one.
A better solution is to use Dan Fabulich's waitForCondition extension. But first, a word about Selenium extensions.
If you've never installed a Selenium extension, it's actually pretty easy. You should have a file called user-extensions.js.sample in the same directory where you installed the other core Selenium files (such as TestRunner.html and selenium-api.js). You need to rename that file as user-extensions.js, so that it will be automatically picked up by Selenium the next time you run a test. To install a specific extension such as waitForCondition, you need to download and unpack the extension's zip file, then add the contents of the user-extensions.js.waitForCondition file to user-extensions.js. That's all there is to it.
Now back to testing Ajax functionality. For the MailOnnaStick application, Titus and I used Ian Bicking's Commentary application as an example of Ajax-specific functionality that we wanted to test with Selenium. See this post of mine for details on how Commentary works and how we wrote our initial tests. The approach we took initially was the one I mentioned in the beginning, namely putting pause commands before the Ajax-specific asserts. Interestingly enough, this was the only Selenium test that was breaking consistently in our buildbot setup, precisely because of speed differences between the machines that were running buildbot. So I rewrote the tests using waitForCondition.
What does waitForCondition buy you? It allows you to include arbitrary Javascript code in your commands and assert that a condition (written in Javascript) is true. The test will not advance until the condition becomes true (hence the wait prefix). Or, to put it in the words of Dan Fabulich:
waitForCondition: Waits for any arbitrary condition, by running a JavaScript snippet of your choosing. When the snippet evaluates to "true", we stop waiting.
Here's a quick example of a Selenium test table row that uses waitForCondition (note that the last value in the 3rd cell is a timeout value, in milliseconds):
What I'm doing here is asserting that a certain HTML element is present in the page under test. For the Commentary functionality, the element I chose is the text area of the form that pops up when you double-click on the page. This element did not exist before the double-click event, so by asserting that its value is empty, I make sure that it exists, which means that the asynchronous Ajax call has completed. If the element is not there after the timeout has expired (10 seconds in my case), the assertion is marked as failed.
To get to the element, I used the special variable selenium, which is available for use in Javascript commands that you want to embed in your Selenium tables. The methods that you can call on this variable are the same methods that start with Selenium.prototype in the file selenium-api.js. In this case, I called getText, which is defined as follows in selenium-api.js:
Selenium.prototype.getText = function(locator) {
var element = this.page().findElement(locator);
return getText(element).trim();
};
This function gets a locator as its only argument. In the example above, I used the XPath-style locator "//textarea[@name='comment']" -- which means "give me the HTML element identified by the tag textarea, and whose attribute name has the value 'comment'". The value of this HTML element is empty, so this is exactly what I'm asserting in the test table: value == "".
You might wonder how I figured out which element to use in the assertion. Easy: I inspected the HTML source of the page under test before and after I double-clicked on the page, and I identified an element which was present only after the double-click event.
The other scenario I had to test was that the Commentary post-it note is not present anymore after deleting the commentary. Again, I looked at the HTML page under test before and after clicking on the Delete link, and I identified an element which was present before, and not present after the deletion. Here is the waitForCondition assertion I came up with:
Here I used selenium.page() to get to the HTML page under test, then bodyText() to get to the text of the body tag. I then searched for the text that I was NOT expecting to find anymore, and I asserted that the Javascript indexOf() method returned -1 (i.e. the text was indeed not found.)
Here is the test table for the Commentary functionality in its entirety:
For more details on how to identify HTML elements that you want to test using Selenium test tables, see this post on useful Selenium tools, and this post on using the Selenium IDE.
Update: Since images are worth thousands and thousands of words, here are 2 screencasts (no sound) of running the Commentary test with Selenium: one in Windows AVI format, and the other one in Quicktime MOV format (you might be better off saving the files to your local disk before viewing them.)
A better solution is to use Dan Fabulich's waitForCondition extension. But first, a word about Selenium extensions.
If you've never installed a Selenium extension, it's actually pretty easy. You should have a file called user-extensions.js.sample in the same directory where you installed the other core Selenium files (such as TestRunner.html and selenium-api.js). You need to rename that file as user-extensions.js, so that it will be automatically picked up by Selenium the next time you run a test. To install a specific extension such as waitForCondition, you need to download and unpack the extension's zip file, then add the contents of the user-extensions.js.waitForCondition file to user-extensions.js. That's all there is to it.
Now back to testing Ajax functionality. For the MailOnnaStick application, Titus and I used Ian Bicking's Commentary application as an example of Ajax-specific functionality that we wanted to test with Selenium. See this post of mine for details on how Commentary works and how we wrote our initial tests. The approach we took initially was the one I mentioned in the beginning, namely putting pause commands before the Ajax-specific asserts. Interestingly enough, this was the only Selenium test that was breaking consistently in our buildbot setup, precisely because of speed differences between the machines that were running buildbot. So I rewrote the tests using waitForCondition.
What does waitForCondition buy you? It allows you to include arbitrary Javascript code in your commands and assert that a condition (written in Javascript) is true. The test will not advance until the condition becomes true (hence the wait prefix). Or, to put it in the words of Dan Fabulich:
waitForCondition: Waits for any arbitrary condition, by running a JavaScript snippet of your choosing. When the snippet evaluates to "true", we stop waiting.
Here's a quick example of a Selenium test table row that uses waitForCondition (note that the last value in the 3rd cell is a timeout value, in milliseconds):
| waitForCondition | var value = selenium.getText("//textarea[@name='comment']"); value == "" | 10000 |
What I'm doing here is asserting that a certain HTML element is present in the page under test. For the Commentary functionality, the element I chose is the text area of the form that pops up when you double-click on the page. This element did not exist before the double-click event, so by asserting that its value is empty, I make sure that it exists, which means that the asynchronous Ajax call has completed. If the element is not there after the timeout has expired (10 seconds in my case), the assertion is marked as failed.
To get to the element, I used the special variable selenium, which is available for use in Javascript commands that you want to embed in your Selenium tables. The methods that you can call on this variable are the same methods that start with Selenium.prototype in the file selenium-api.js. In this case, I called getText, which is defined as follows in selenium-api.js:
Selenium.prototype.getText = function(locator) {
var element = this.page().findElement(locator);
return getText(element).trim();
};
This function gets a locator as its only argument. In the example above, I used the XPath-style locator "//textarea[@name='comment']" -- which means "give me the HTML element identified by the tag textarea, and whose attribute name has the value 'comment'". The value of this HTML element is empty, so this is exactly what I'm asserting in the test table: value == "".
You might wonder how I figured out which element to use in the assertion. Easy: I inspected the HTML source of the page under test before and after I double-clicked on the page, and I identified an element which was present only after the double-click event.
The other scenario I had to test was that the Commentary post-it note is not present anymore after deleting the commentary. Again, I looked at the HTML page under test before and after clicking on the Delete link, and I identified an element which was present before, and not present after the deletion. Here is the waitForCondition assertion I came up with:
| waitForCondition | var allText = selenium.page().bodyText(); var unexpectedText = "hello there from user${var}" allText.indexOf(unexpectedText) == -1; | 10000 |
Here I used selenium.page() to get to the HTML page under test, then bodyText() to get to the text of the body tag. I then searched for the text that I was NOT expecting to find anymore, and I asserted that the Javascript indexOf() method returned -1 (i.e. the text was indeed not found.)
Here is the test table for the Commentary functionality in its entirety:
| TestCommentary | ||
| open | /message/20050409174524.GA4854@highenergymagic.org | |
| dblclick | //blockquote | |
| waitForCondition | var value = selenium.getText("//textarea[@name='comment']"); value == "" | 10000 |
| store | javascript{Math.round(1000*Math.random())} | var |
| type | username | user${var} |
| type | user${var}@mos.org | |
| type | comment | hello there from user${var} |
| click | //form//button[1] | |
| waitForCondition | var value = selenium.getText("//div[@class='commentary-comment commentary-inline']"); value.match(/hello there from user${var}/); | 10000 |
| verifyText | //div[@class="commentary-comment commentary-inline"] | regexp:hello there from user${var} |
| clickAndWait | //div/div[position()="1" and @style="font-size: 80%;"]/a[position()="2" and @href="/search"] | |
| type | q | user${var} |
| clickAndWait | //input[@type='submit' and @value='search'] | |
| verifyValue | q | user${var} |
| assertTextPresent | Query: user${var} | |
| assertTextPresent | in Re: [socal-piggies] meeting Tues Apr 12th: confirmed | |
| open | /message/20050409174524.GA4854@highenergymagic.org | |
| assertTextPresent | hello there from user${var} | |
| assertTextPresent | delete | |
| click | link=delete | |
| waitForCondition | var allText = selenium.page().bodyText(); var unexpectedText = "hello there from user${var}" allText.indexOf(unexpectedText) == -1; | 10000 |
| assertTextNotPresent | hello there from user${var} | |
| assertTextNotPresent | delete | |
| clickAndWait | //div/div[position()="1" and @style="font-size: 80%;"]/a[position()="2" and @href="/search"] | |
| type | q | user${var} |
| clickAndWait | //input[@type='submit' and @value='search'] | |
| verifyValue | q | user${var} |
| assertTextPresent | Query: user${var} | |
| assertTextPresent | no matches | |
For more details on how to identify HTML elements that you want to test using Selenium test tables, see this post on useful Selenium tools, and this post on using the Selenium IDE.
Update: Since images are worth thousands and thousands of words, here are 2 screencasts (no sound) of running the Commentary test with Selenium: one in Windows AVI format, and the other one in Quicktime MOV format (you might be better off saving the files to your local disk before viewing them.)
Monday, March 20, 2006
Elizabeth Hendrickson on "Better testing, worse testing"
I've always enjoyed Elisabeth Hendrickson's articles and blog posts on testing. Her latest post, "Better Testing, Worse Testing", confirms one of the two main conclusions Titus and I reached while working on our PyCon Agile Testing tutorial. Here's an excerpt from the Wrap-up section of our tutorial handout notes:
Again, holistic testing.
What was our second main conclusion for the tutorial? Continous integration! Here's another excerpt from the handout notes, the second bullet point under Wrap-up and Conclusions:
Make it as easy as humanly possible to run all these types of tests automatically, or they will not get run.
Wrap up & Conclusions
- Holistic testing is the way to go. No one test type does it all...
- unit testing of basic code
- Functional/acceptance testing of business/user logic
- regression testing
Again, holistic testing.
What was our second main conclusion for the tutorial? Continous integration! Here's another excerpt from the handout notes, the second bullet point under Wrap-up and Conclusions:
Make it as easy as humanly possible to run all these types of tests automatically, or they will not get run.
PTTT updates
Several people updated the Python Testing Tools Taxonomy Wiki page in the last couple of months. Here are some tools that were added:
- pywinauto (added by its author Mark McMahon): "Simple Windows (NT/2K/XP) GUI automation with Python. There are tests included for Localization testing but there is no limitation to this. Most of the code at the moment is for recovering information from Windows windows and performing actions on those controls. The idea is to have high level methods for standard controls rather then rely on Sending keystrokes to the applications."
- svnmock (added by its author Collin Winter): "enables easier testing of Python programs that make use of Subversion's Python bindings."
- testosterone (added by its author Chad Whitacre): "an interface for running tests written with the Python standard library's unittest module. It delivers summary and detail reports on TestCases discovered in module-space, via both a command-line and a curses interface. The interactive mode is the default, but it depends on the non-interactive mode. For debugging, static tracebacks and interactive Python debugger (Pdb) sessions are available in both scripted and interactive modes."
- Bitten (added by Matt Good, written by Christopher Lenz): "a Python-based framework for collecting various software metrics via continuous integration. It builds on Trac to provide an integrated web-based user interface."
- pyMetrics (added by Mark Garboden, written by Reginald B. Charney): "produces metrics for Python programs. Metrics include McCabe's Cyclomatic Complexity metric, LoC, %Comments, etc. Users can also define their own metrics using data from PyMetrics. PyMetrics outputs SQL command files and CSV output."
- trace2html (added by its author Olivier Grisel): "utility to convert execution coverage data obtained with the `trace` module of the standard python library into a set of human
readable HTML documents showing sortable summary and annotated source files." - pyAA (added by myself, written by the Carolina Computer Assistive Technology group at UNC-Chapel Hill): "an object oriented Python wrapper around the client-side functionality in the Microsoft Active Accessibility (MSAA) library. MSAA is a library for the Windows platform that allows client applications inspect, control, and monitor events and controls in graphical user interfaces (GUIs) and server applications to expose runtime information about their user interfaces. See Peter Parente's User interface automation with pyAA tutorial for more info."
Nuxeo mentioned in news.com article on Eclipse
I was glad to see Nuxeo mentioned in a news.com article on Eclipse. Nuxeo offers an open-source content management product called CPS, which uses Zope. The reason I know about them is that I've been in touch with several people who work there and who are very interested in Python testing tools and techniques. As a matter of fact, they released a functional/performance testing tool written in Python, called FunkLoad. Plus they're early adopters of Cheesecake :-)
Friday, March 17, 2006
They still teach Waterfall in schools
The last few days I've interviewed some candidates for an entry-level QA position at the company where I work . All of them were fresh graduates of local universities, some from the University of California system, some from the Cal State system. All of them had something in common though: they very seriously explained to me how they took classes in "Software Development Lifecycle" and how they worked on toy projects, first obtaining requirements, then designing, then implementing, then at the very end, if they had time, doing some manual testing. Of course, no word of automated testing, iterations, or other agile concepts. At least they used source control (CVS).
One guy in particular told me kind of proudly that he knows all about the Waterfall methodology. He said they spent a lot of time writing design documents, and since they *only* had one semester for the whole project, they almost didn't get to code at all. I couldn't help laughing at that point, and I told him that maybe that should have been a red flag concerning the validity of the Waterfall methodology. I couldn't have found a better counter-example to Waterfall myself if I tried. Almost no code at all to show at the end of the semester, but they razed half of a forest with their so-called documentation!
Of course, I tried to gently push them on the path to enlightenment, briefly explaining that there are other ways to approach software development and testing. One can always try at least, right?
Another thing that irked me was that, since they knew this is an interview for a QA position, some of the candidates thought it necessary to tell me they're busily learning WinRunner. I told them in a nice and gentle manner that I don't give a *beeeeep* about WinRunner, and that there are many Open Source tools they can leverage. One of them said that yes, that may be true, but still many companies require a knowledge of WinRunner for QA positions, so you just *need* to put it on your resume. Sigh. The battles one has to fight...
If I'm happy about one thing from this whole experience, it's that all those people left with their vocabulary enriched with a few choice words: Open Source, Python, scripting, automated testing, continuous integration, buildbot, etc. You never know what grows out of even tiny seeds you plant...
It amazes me though how out of touch many schools are with the realities of software development. If I were in charge of the CS program at a university, I'd make it a requisite for all students to work through Greg Wilson's Software Carpentry lectures at the University of Toronto. I particularly like the lectures on The Development Process and Teamware. Unfortunately, stuff like this seems to be the exception rather than the norm.
One guy in particular told me kind of proudly that he knows all about the Waterfall methodology. He said they spent a lot of time writing design documents, and since they *only* had one semester for the whole project, they almost didn't get to code at all. I couldn't help laughing at that point, and I told him that maybe that should have been a red flag concerning the validity of the Waterfall methodology. I couldn't have found a better counter-example to Waterfall myself if I tried. Almost no code at all to show at the end of the semester, but they razed half of a forest with their so-called documentation!
Of course, I tried to gently push them on the path to enlightenment, briefly explaining that there are other ways to approach software development and testing. One can always try at least, right?
Another thing that irked me was that, since they knew this is an interview for a QA position, some of the candidates thought it necessary to tell me they're busily learning WinRunner. I told them in a nice and gentle manner that I don't give a *beeeeep* about WinRunner, and that there are many Open Source tools they can leverage. One of them said that yes, that may be true, but still many companies require a knowledge of WinRunner for QA positions, so you just *need* to put it on your resume. Sigh. The battles one has to fight...
If I'm happy about one thing from this whole experience, it's that all those people left with their vocabulary enriched with a few choice words: Open Source, Python, scripting, automated testing, continuous integration, buildbot, etc. You never know what grows out of even tiny seeds you plant...
It amazes me though how out of touch many schools are with the realities of software development. If I were in charge of the CS program at a university, I'd make it a requisite for all students to work through Greg Wilson's Software Carpentry lectures at the University of Toronto. I particularly like the lectures on The Development Process and Teamware. Unfortunately, stuff like this seems to be the exception rather than the norm.
Tuesday, March 14, 2006
Buildbot Technology Narrative
Titus just put the finishing touches on a very fast-paced and entertaining Buildbot Technology Narrative page on the Agile Testing wiki we used for our PyCon tutorial. Highly recommended if you're curious to see how a continuous integration tool such as buildbot can be used to...well, to integrate all the types of automated tests that we used in our tutorial.
Comments/suggestions appreciated. Please leave them here or send them via email to titus at caltech.edu or grig at gheorghiu.net.
Comments/suggestions appreciated. Please leave them here or send them via email to titus at caltech.edu or grig at gheorghiu.net.
Thursday, March 09, 2006
"Articles and Tutorials" page updated
I decided to move the "Articles and Tutorials" page to a different server, since it's annoying to publish it here every time I make a change to it. I'll probably host it here again when Blogger decides to implement categories...
Wednesday, March 08, 2006
Running buildbot on various platforms
I started to run a bunch of buildbot slaves at work, on various platforms. I encountered some issues that I want to document here for future reference. The version of buildbot I used in all scenarios was 0.7.2. The buildbot master is running on a RHEL3 server. Note that I'm not going to talk about the general buildbot setup -- if you need guidance in configuring buildbot, read this post of mine.
Before I discuss platform-specific issues, I want to mention the issue of timeouts. If you want to run a command that takes a long time on the buildbot slave, you need to increase the default timeout (which is 1200 sec. = 20 min.) for the ShellCommand definitions in the buildmaster's master.cfg file -- otherwise, the master will mark that command as failed after the timeout expires. To modify the default timeout, simply add a keyword argument such as timeout=3600 to the ShellCommand (or derived class) instantiation in master.cfg. I have for example this line in the builders section of my master.cfg file:
client_smoke_tests = s(ClientSmokeTests, command="%s/buildbot/run_smoke_tests.py" % BUILDBOT_PATH, timeout=3600)
where ClientSmokeTests is a class I derived from ShellCommand (if you need details on this, see again my previous post on buildbot.)
Buildbot on Windows
My setup: Windows 2003 server, Active Python 2.4.2
Issue with subprocess module: I couldn't use the subprocess module to run commands on the slave. I got errors such as these:
I didn't have too much time to spend troubleshooting this, so I ended up replacing calls to subprocess to calls to popen2.popen3(). This solved the problem.
Also, I'm not currently running the buildbot process as a Windows service, although it's on my TODO list. I wrote a simple .bat file which I called startbot.bat:
buildbot start C:\qa\pylts\buildbot\QA
To start buildbot, I launched startbot.bat from the command prompt and I left it running.
Note that on Windows, the buildbot script gets installed in C:\Python24\scripts, and there is also a buildbot.bat batch file in the same scripts directory, which calls the buildbot script.
Issue with buildbot.bat: it contains a hardcoded path to Python23. I had to change that to Python24 so that it correctly finds the buildbot script in C:\Python24\scripts.
Buildbot on Solaris
My setup: one Solaris 9 SPARC server, one Solaris 10 SPARC server, both running Python 2.3.3
Issue with ZopeInterface on Solaris 10: when I tried to install ZopeInterface via 'easy_install http://www.zope.org/Products/ZopeInterface/3.1.0c1/ZopeInterface-3.1.0c1.tgz', a compilation step failed with:
/usr/include/sys/wait.h:86: error: parse error before "siginfo_t"
A google search revealed that this was a gcc-related issue specific to Solaris 10. Based on this post, I ran:
# cd /usr/local/lib/gcc-lib/sparc-sun-solaris2.10/3.3.2/install-tools
# ./mkheaders
After these steps, I was able to install ZopeInterface and the rest of the packages required by buildbot.
For reference, here is what I have on the Solaris 10 box in terms of gcc packages:
# pkginfo | grep -i gcc
system SFWgcc2 gcc-2 - GNU Compiler Collection
system SFWgcc2l gcc-2 - GNU Compiler Collection Runtime Libraries
system SFWgcc34 gcc-3.4.2 - GNU Compiler Collection
system SFWgcc34l gcc-3.4.2 - GNU Compiler Collection Runtime Libraries
application SMCgcc gcc
system SUNWgcc gcc - The GNU C compiler
system SUNWgccruntime GCC Runtime libraries
Here is what uname -a returns:
# uname -a
SunOS sunv2403 5.10 Generic sun4u sparc SUNW,Sun-Fire-V240
Issue with exit codes from child processes not intercepted correctly: on both Solaris 9 and Solaris 10, buildbot didn't seem to intercept correctly the exit code from the scripts which were running on the build slaves. I was able to check that I had the correct exit codes by running the scripts at the command line, but within buildbot the scripts just hung as if they hadn't finish.
Some searches on the buildbot-devel mailing list later, I found the solution via this post: I replaced usepty = 1 with usepty = 0 in buildbot.tac on the Solaris slaves, then I restarted the buildbot process on the slaves, and everything was fine.
Buildbot on AIX
My setup: AIX 5.2 on an IBM P510 server, Python 2.4.1
No problems here. Everything went smoothly.
Before I discuss platform-specific issues, I want to mention the issue of timeouts. If you want to run a command that takes a long time on the buildbot slave, you need to increase the default timeout (which is 1200 sec. = 20 min.) for the ShellCommand definitions in the buildmaster's master.cfg file -- otherwise, the master will mark that command as failed after the timeout expires. To modify the default timeout, simply add a keyword argument such as timeout=3600 to the ShellCommand (or derived class) instantiation in master.cfg. I have for example this line in the builders section of my master.cfg file:
client_smoke_tests = s(ClientSmokeTests, command="%s/buildbot/run_smoke_tests.py" % BUILDBOT_PATH, timeout=3600)
where ClientSmokeTests is a class I derived from ShellCommand (if you need details on this, see again my previous post on buildbot.)
Buildbot on Windows
My setup: Windows 2003 server, Active Python 2.4.2
Issue with subprocess module: I couldn't use the subprocess module to run commands on the slave. I got errors such as these:
p = Popen(arglist, stdout=PIPE, stderr=STDOUT)
File "C:\Python24\lib\subprocess.py", line 533, in __init__
(p2cread, p2cwrite,
File "C:\Python24\lib\subprocess.py", line 593, in _get_handles
p2cread = self._make_inheritable(p2cread)
File "C:\Python24\lib\subprocess.py", line 634, in _make_inheritable
DUPLICATE_SAME_ACCESS)
TypeError: an integer is requiredI didn't have too much time to spend troubleshooting this, so I ended up replacing calls to subprocess to calls to popen2.popen3(). This solved the problem.
Also, I'm not currently running the buildbot process as a Windows service, although it's on my TODO list. I wrote a simple .bat file which I called startbot.bat:
buildbot start C:\qa\pylts\buildbot\QA
To start buildbot, I launched startbot.bat from the command prompt and I left it running.
Note that on Windows, the buildbot script gets installed in C:\Python24\scripts, and there is also a buildbot.bat batch file in the same scripts directory, which calls the buildbot script.
Issue with buildbot.bat: it contains a hardcoded path to Python23. I had to change that to Python24 so that it correctly finds the buildbot script in C:\Python24\scripts.
Buildbot on Solaris
My setup: one Solaris 9 SPARC server, one Solaris 10 SPARC server, both running Python 2.3.3
Issue with ZopeInterface on Solaris 10: when I tried to install ZopeInterface via 'easy_install http://www.zope.org/Products/ZopeInterface/3.1.0c1/ZopeInterface-3.1.0c1.tgz', a compilation step failed with:
/usr/include/sys/wait.h:86: error: parse error before "siginfo_t"
A google search revealed that this was a gcc-related issue specific to Solaris 10. Based on this post, I ran:
# cd /usr/local/lib/gcc-lib/sparc-sun-solaris2.10/3.3.2/install-tools
# ./mkheaders
After these steps, I was able to install ZopeInterface and the rest of the packages required by buildbot.
For reference, here is what I have on the Solaris 10 box in terms of gcc packages:
# pkginfo | grep -i gcc
system SFWgcc2 gcc-2 - GNU Compiler Collection
system SFWgcc2l gcc-2 - GNU Compiler Collection Runtime Libraries
system SFWgcc34 gcc-3.4.2 - GNU Compiler Collection
system SFWgcc34l gcc-3.4.2 - GNU Compiler Collection Runtime Libraries
application SMCgcc gcc
system SUNWgcc gcc - The GNU C compiler
system SUNWgccruntime GCC Runtime libraries
Here is what uname -a returns:
# uname -a
SunOS sunv2403 5.10 Generic sun4u sparc SUNW,Sun-Fire-V240
Issue with exit codes from child processes not intercepted correctly: on both Solaris 9 and Solaris 10, buildbot didn't seem to intercept correctly the exit code from the scripts which were running on the build slaves. I was able to check that I had the correct exit codes by running the scripts at the command line, but within buildbot the scripts just hung as if they hadn't finish.
Some searches on the buildbot-devel mailing list later, I found the solution via this post: I replaced usepty = 1 with usepty = 0 in buildbot.tac on the Solaris slaves, then I restarted the buildbot process on the slaves, and everything was fine.
Buildbot on AIX
My setup: AIX 5.2 on an IBM P510 server, Python 2.4.1
No problems here. Everything went smoothly.
Tuesday, March 07, 2006
Mind mapping
I first encountered the concept of mind maps when I read the 1st edition of "Extreme programming explained" by Kent Beck. I've wanted for a long time to delve more into this subject, but it's only now that I got around to it by reading "Mind maps at work" by Tony Buzan, the inventor of mind maps.
To put it briefly, a mind map is a graph-like structure that starts with a central image of the concept you're trying to focus on. You then start drawing branches radiating out from the center, and on each branch you write some quality or feature of the central concept. Then you draw smaller branches, twigs if you want, with more and more details pertaining to each branch. Since a picture is worth a thousand words, here's a mind map I drew while brainstorming about ways to approach automated testing (apologies for the poor quality of my handwriting):
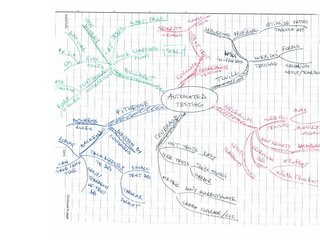
The beauty of this is that I was able to summarize in a single page almost all the concepts that Titus and I presented during our PyCon tutorial! Pretty amazing if you ask me....
One thing that Tony Buzan recommends, and that I found very helpful, is to use different colors for the different branches of the mind map. This is because one of the main strengths, if not the main strength of mind maps, is to engage both sides of your brain -- and using color helps exercising the often neglected right side. The usual method of describing a concept by using linear lists and slides with bullet points is much more analytical, and tends to engage only the left side of the brain.
I find that when I draw a mind map by hand and when I use color, I tend to brainstorm a lot more, and I tend to find new associations between concepts. Because everything is on one page, it's easy to see the big picture and to start connecting things in sometimes surprising ways...
I even managed to get my kids interested in mind maps (lesson learned: it's much better to get your points accross to your kids if they see you doing something you're excited about, rather than just talking/preaching about it...). They've used them so far for inventing new video games -- I'm hoping they'll also use them when they study for Social Studies or Science :-)
I'm pretty excited about mind maps and I plan on using them intensively on my projects. Highly recommended!
To put it briefly, a mind map is a graph-like structure that starts with a central image of the concept you're trying to focus on. You then start drawing branches radiating out from the center, and on each branch you write some quality or feature of the central concept. Then you draw smaller branches, twigs if you want, with more and more details pertaining to each branch. Since a picture is worth a thousand words, here's a mind map I drew while brainstorming about ways to approach automated testing (apologies for the poor quality of my handwriting):
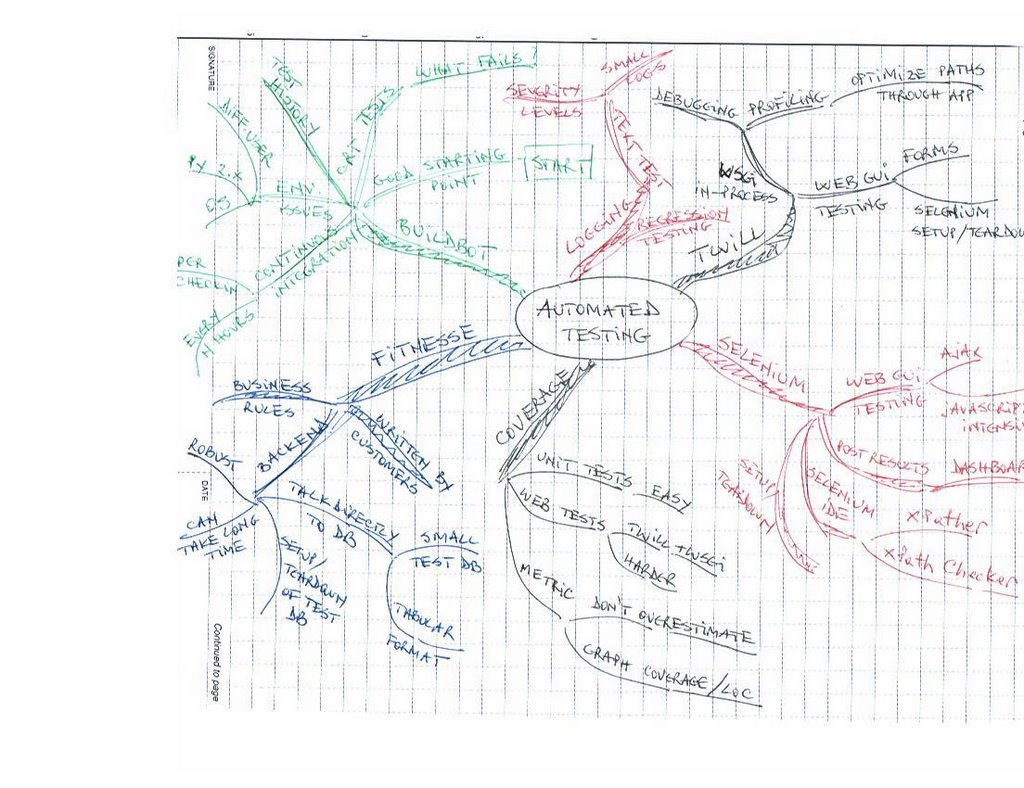
The beauty of this is that I was able to summarize in a single page almost all the concepts that Titus and I presented during our PyCon tutorial! Pretty amazing if you ask me....
One thing that Tony Buzan recommends, and that I found very helpful, is to use different colors for the different branches of the mind map. This is because one of the main strengths, if not the main strength of mind maps, is to engage both sides of your brain -- and using color helps exercising the often neglected right side. The usual method of describing a concept by using linear lists and slides with bullet points is much more analytical, and tends to engage only the left side of the brain.
I find that when I draw a mind map by hand and when I use color, I tend to brainstorm a lot more, and I tend to find new associations between concepts. Because everything is on one page, it's easy to see the big picture and to start connecting things in sometimes surprising ways...
I even managed to get my kids interested in mind maps (lesson learned: it's much better to get your points accross to your kids if they see you doing something you're excited about, rather than just talking/preaching about it...). They've used them so far for inventing new video games -- I'm hoping they'll also use them when they study for Social Studies or Science :-)
I'm pretty excited about mind maps and I plan on using them intensively on my projects. Highly recommended!
Monday, March 06, 2006
Remote Web app testing with Selenium IDE
If you've been using standard -- aka "table-mode" -- Selenium to test your Web application, you know that the static Selenium files, as well as your custom test files and suites, need to be deployed under the root of your Web application, on the same server that hosts the app. This is because Selenium uses JavaScript, and JavaScript has a built-in security limitation to prevent cross-site scripting attacks against Web servers.
The good news is that if you're using Firefox, you're in luck -- you can pretty much bypass this limitation thanks to the wonderful Firefox extension called Selenium IDE (used to be called Selenium Recorder.) I talked about the Selenium Recorder and other useful Firefox extensions in a previous post. What I want to show here is how easy it is to write Selenium tests, even against 3rd party applications, by using Selenium IDE.
I'll assume you already installed Selenium IDE. You need to launch it via the Firefox Tools menu. It will open a new Firefox window that you just leave running in the background.
Now let's say I want to test some Google searches, this being the canonical example used by people who want to play with Web testing tools. I go to google.com, I type "pycon 2006", then I click on the link pointing to the official PyCon 2006 site. While I'm on the PyCon page, I highlight the text "Welcome to PyCon 2006", I right-click and choose "assertTextPresent Welcome to PyCon 2006" from the pop-up menu that comes up (of course, I realize that a screencast would be better at this point, but it needs to wait for now....)
If you followed along, you'll notice that the Selenium IDE window contains actions such as type and clickAndWait, as well as validation statements such as assertTitle and assertTextPresent. In fact, Selenium IDE just created a Selenium test case for you. Here's a snapshot of what I have at this point:

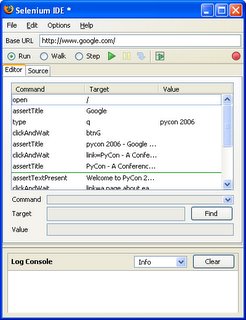
Now you have several options for replaying and saving the current test.
You can click on the large green arrow button. This will replay the actions in a Firefox window and will color the Selenium IDE assertion rows green or red, depending on the result of the actions.
You can also click on the smaller green arrow button, to the right on the Selenium IDE. This will open a new Firefox window and will show the test in the familiar Selenium TestRunner mode, something like this:
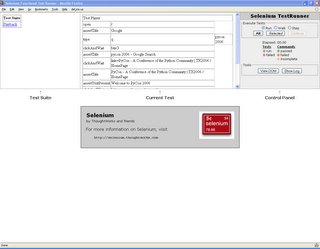
At this point, you can run the test in the standard TestRunner mode, by clicking for example on the Run button in the TestRunner Control Panel.
Note however the URL of the test:
chrome://selenium-ide/content/selenium/TestRunner.html?test=/content/PlayerTestSuite.html&userExtensionsURL=&baseURL=http://www.google.com/
The URL doesn't use the http protocol, but instead uses the chrome protocol specific to Firefox. The fact that Selenium IDE is a Firefox extension give it access to the chrome protocol and allows it to get around the JavaScript XSS security limitation.
At this point, you can also save the test by choosing File->Save Test or pressing Ctrl-S in the Selenium IDE. The test will be saved as an HTML file.
Selenium IDE also allows you to test both http and https within the same application. Normally, without the Selenium IDE, you need to choose at the start of your test whether you want to test pages accessible via http, or pages accessible via https. Once you make this choice, you can't switch from http to https or from https to http within the same test, because of the dreaded JavaScript XSS security limitation. With Selenium IDE, however, you can open both kinds of pages within a single test.
An important note: all this Selenium IDE hocus-pocus does lock you in on Firefox. As soon as you start testing pages that are not under your application root, or you start mixing http and https in your tests, you will not be able to run the same tests under IE, Camino, Safari or other browsers -- at least not until people come up with browser-specific extensions that will get around the XSS limitation.
If you want your tests to be portable across browsers, you can still use Selenium IDE to create the tests. You just need to make sure you test pages that are within your application, and that use the same protocol throughout the test. After saving the tests as local HTML files, you need to copy them over to the Selenium installation that you have deployed on the server hosting the application under test. In any case, I urge you to start using Selenium IDE. It will give you a major productivity boost in writing Selenium tests. There are other features of the IDE that I haven't covered here (after all, it's meant to be an IDE, and not only a playback/capture tool), but for this I'll let you read the online documentation or, even better, watch the movie.
The good news is that if you're using Firefox, you're in luck -- you can pretty much bypass this limitation thanks to the wonderful Firefox extension called Selenium IDE (used to be called Selenium Recorder.) I talked about the Selenium Recorder and other useful Firefox extensions in a previous post. What I want to show here is how easy it is to write Selenium tests, even against 3rd party applications, by using Selenium IDE.
I'll assume you already installed Selenium IDE. You need to launch it via the Firefox Tools menu. It will open a new Firefox window that you just leave running in the background.
Now let's say I want to test some Google searches, this being the canonical example used by people who want to play with Web testing tools. I go to google.com, I type "pycon 2006", then I click on the link pointing to the official PyCon 2006 site. While I'm on the PyCon page, I highlight the text "Welcome to PyCon 2006", I right-click and choose "assertTextPresent Welcome to PyCon 2006" from the pop-up menu that comes up (of course, I realize that a screencast would be better at this point, but it needs to wait for now....)
If you followed along, you'll notice that the Selenium IDE window contains actions such as type and clickAndWait, as well as validation statements such as assertTitle and assertTextPresent. In fact, Selenium IDE just created a Selenium test case for you. Here's a snapshot of what I have at this point:
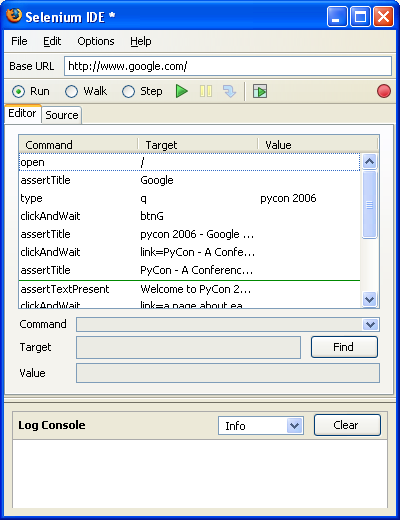
Now you have several options for replaying and saving the current test.
You can click on the large green arrow button. This will replay the actions in a Firefox window and will color the Selenium IDE assertion rows green or red, depending on the result of the actions.
You can also click on the smaller green arrow button, to the right on the Selenium IDE. This will open a new Firefox window and will show the test in the familiar Selenium TestRunner mode, something like this:

At this point, you can run the test in the standard TestRunner mode, by clicking for example on the Run button in the TestRunner Control Panel.
Note however the URL of the test:
chrome://selenium-ide/content/selenium/TestRunner.html?test=/content/PlayerTestSuite.html&userExtensionsURL=&baseURL=http://www.google.com/
The URL doesn't use the http protocol, but instead uses the chrome protocol specific to Firefox. The fact that Selenium IDE is a Firefox extension give it access to the chrome protocol and allows it to get around the JavaScript XSS security limitation.
At this point, you can also save the test by choosing File->Save Test or pressing Ctrl-S in the Selenium IDE. The test will be saved as an HTML file.
Selenium IDE also allows you to test both http and https within the same application. Normally, without the Selenium IDE, you need to choose at the start of your test whether you want to test pages accessible via http, or pages accessible via https. Once you make this choice, you can't switch from http to https or from https to http within the same test, because of the dreaded JavaScript XSS security limitation. With Selenium IDE, however, you can open both kinds of pages within a single test.
An important note: all this Selenium IDE hocus-pocus does lock you in on Firefox. As soon as you start testing pages that are not under your application root, or you start mixing http and https in your tests, you will not be able to run the same tests under IE, Camino, Safari or other browsers -- at least not until people come up with browser-specific extensions that will get around the XSS limitation.
If you want your tests to be portable across browsers, you can still use Selenium IDE to create the tests. You just need to make sure you test pages that are within your application, and that use the same protocol throughout the test. After saving the tests as local HTML files, you need to copy them over to the Selenium installation that you have deployed on the server hosting the application under test. In any case, I urge you to start using Selenium IDE. It will give you a major productivity boost in writing Selenium tests. There are other features of the IDE that I haven't covered here (after all, it's meant to be an IDE, and not only a playback/capture tool), but for this I'll let you read the online documentation or, even better, watch the movie.
Wednesday, March 01, 2006
Should acceptance tests talk to the database?
There's an ongoing discussion on the FitNesse mailing list about whether acceptance tests should talk to a "real" database or should instead use mock objects to test the business rules. To me, acceptance tests, especially the ones written in Fit/FitNesse, are customer-facing (a term coined I believe by Brian Marick), and hence they need to give customers a warm and fuzzy feeling that they're actually proving something about the system as a whole. The closer the environment is to the customer's production environment, the better in this case. Here's my initial message to the list:
I would say that since you're doing *acceptance* testing, it doesn't make too much sense to mock the database. Mocking makes more sense in a unit testing situation. But for acceptance testing, the way I see it is to mimic the customer environment as much as possible, and that involves setting up a test database which is as similar as possible to the production database. Of course, if you have a huge production database, it is not optimal to have the same sized test database, so what I'd do is extract datasets with certain characteristics from the production db and populate the test db with them. I'd choose corner cases, etc.
A couple of other people replied to the initial post and said they think that "pure business rules" should also be exercised by mocking the backend and testing the application against data that can come from any source. While I think that this is a good idea, I see its benefit mainly in an overall improvement of the code. If you think about testing the business rules independent of the actual backend, you will have to refactor your code so that you encapsulate the backend-specific functionality as tightly as possible. This results in better code which is more robust and more testable. However, this is a developer-facing issue, not necessarily a customer-facing one. The customers don't necessarily care, as far as their acceptance tests are concerned, how you organize your code. They care that the application does what they want it to do. In this case, "end-to-end" testing that involves a real database is I think necessary.
In this context, Janniche Haugen pointed me to a great article written by David Chelimsky: Fostering Credibility In Customer Tests. David talks about the confusion experienced by customers when they don't know exactly what the tests do, especially when there's a non-obvious configuration option which can switch from a "real database" test to a "fake in-memory database" test. Maybe what's needed in this case is to label the tests in big bold letters on the FitNesse wiki pages: "END TO END TESTS AGAINST A LIVE DATABASE" vs. "PURE BUSINESS LOGIC TESTS AGAINST MOCK OBJECTS". At least everybody would be on the same (wiki) page.
My conclusion is that for optimal results, you need to do both kinds of testing: at the pure business rule level and at the end-to-end level. The first type of tests will improve your code, while the second one will keep your customers happy. For customer-specific Fit/FitNesse acceptance tests I would concentrate on the end-to-end tests.
I would say that since you're doing *acceptance* testing, it doesn't make too much sense to mock the database. Mocking makes more sense in a unit testing situation. But for acceptance testing, the way I see it is to mimic the customer environment as much as possible, and that involves setting up a test database which is as similar as possible to the production database. Of course, if you have a huge production database, it is not optimal to have the same sized test database, so what I'd do is extract datasets with certain characteristics from the production db and populate the test db with them. I'd choose corner cases, etc.
A couple of other people replied to the initial post and said they think that "pure business rules" should also be exercised by mocking the backend and testing the application against data that can come from any source. While I think that this is a good idea, I see its benefit mainly in an overall improvement of the code. If you think about testing the business rules independent of the actual backend, you will have to refactor your code so that you encapsulate the backend-specific functionality as tightly as possible. This results in better code which is more robust and more testable. However, this is a developer-facing issue, not necessarily a customer-facing one. The customers don't necessarily care, as far as their acceptance tests are concerned, how you organize your code. They care that the application does what they want it to do. In this case, "end-to-end" testing that involves a real database is I think necessary.
In this context, Janniche Haugen pointed me to a great article written by David Chelimsky: Fostering Credibility In Customer Tests. David talks about the confusion experienced by customers when they don't know exactly what the tests do, especially when there's a non-obvious configuration option which can switch from a "real database" test to a "fake in-memory database" test. Maybe what's needed in this case is to label the tests in big bold letters on the FitNesse wiki pages: "END TO END TESTS AGAINST A LIVE DATABASE" vs. "PURE BUSINESS LOGIC TESTS AGAINST MOCK OBJECTS". At least everybody would be on the same (wiki) page.
My conclusion is that for optimal results, you need to do both kinds of testing: at the pure business rule level and at the end-to-end level. The first type of tests will improve your code, while the second one will keep your customers happy. For customer-specific Fit/FitNesse acceptance tests I would concentrate on the end-to-end tests.
Subscribe to:
Posts (Atom)