Monday, March 28, 2011
Working in the multi-cloud with libcloud
I just posted my slides on "Working on the multi-cloud with libcloud" to Slideshare. It's a talk I gave at the SoCal Piggies meeting in February 2011.
Friday, March 25, 2011
ABM - "Always Be Monitoring"
What prompted this post was an incident we had in the very early hours of this past Tuesday, when we started to see a lot of packet loss, increased latency and timeouts between some of our servers hosted at a data center on the US East Coast, and some instances we have running in EC2, also in the US East region. The symptoms were increased error rates in some application calls that we were making from one back-end server cluster at the data center into another back-end cluster in EC2. These errors weren't affecting our customers too much, because all failed requests were posted to various queues and reprocessed.
There had also been network maintenance done that night within the data center, so we weren't sure initially if it's our outbound connectivity into EC2 or general inbound connectivity into EC2 that was the culprit. What was strange (and unexpected) too was that several EC2 availability zones seemed to be affected -- mostly us-east-1d, but we were also seeing increased latency and timeouts into 1b and 1a. That made it hard to decide whether the issue was with EC2 or with us.
Running traceroutes from different source machines (some being our home machines in California, another one being a Rackspace cloud server instance in Chicago) revealed that packet loss and increased latency occurred almost all the time at the same hop: a router within the Level 3 network upstream from the Amazon EC2 network. What was frustrating too was that the AWS Status dashboard showed everything absolutely green. Now you can argue that this wasn't necessarily an EC2 issue, but if I were Amazon I would like to monitor the major inbound network paths into my infrastructure -- especially when it has the potential to affect several availability zones at once.
This whole issue lasted approximately 3.5 hours, then it miraculously stopped. Somebody must have fixed a defective router. Twitter reports from other people experiencing the exact same issue revealed that the issue was seen as fixed for them at the very minute that it was fixed for us too.
This incident brought home a valuable point for me though: we needed more monitors than we had available. We were monitoring connectivity 1) within the data center, 2) within EC2, and 3) between our data center and EC2. However, we also needed to monitor 4) inbound connectivity into EC2 going from sources that were outside of our data center infrastructure. Only by triangulating (for lack of a better term) our monitoring in this manner would we be sure which network path was to blame. Note that we already had Pingdom set up to monitor various URLs within our site, but like I said, the front-end stuff wasn't affected too much by that particular issue that night.
So...the next day we started up a small Rackspace cloud server in Chicago, and a small Linode VPS in Fremont, California, and we added them to our Nagios installation. We run the same exact checks from these servers into EC2 that we run from our data center into EC2. This makes network issues faster to troubleshoot, although unfortunately not easier to solve -- because we could be depending on a 3rd party to solve them.
I guess a bigger point to make, other than ABM/Always Be Monitoring, is OYA/Own Your Availability (I didn't come up with this, I personally first saw it mentioned by the @fastip guys). To me, what this means is to deploy your infrastructure across multiple providers (data centers/clouds) so that you don't have a single point of failure at the provider level. This is obviously easier said than done....but we're working on it as far as our infrastructure goes.
There had also been network maintenance done that night within the data center, so we weren't sure initially if it's our outbound connectivity into EC2 or general inbound connectivity into EC2 that was the culprit. What was strange (and unexpected) too was that several EC2 availability zones seemed to be affected -- mostly us-east-1d, but we were also seeing increased latency and timeouts into 1b and 1a. That made it hard to decide whether the issue was with EC2 or with us.
Running traceroutes from different source machines (some being our home machines in California, another one being a Rackspace cloud server instance in Chicago) revealed that packet loss and increased latency occurred almost all the time at the same hop: a router within the Level 3 network upstream from the Amazon EC2 network. What was frustrating too was that the AWS Status dashboard showed everything absolutely green. Now you can argue that this wasn't necessarily an EC2 issue, but if I were Amazon I would like to monitor the major inbound network paths into my infrastructure -- especially when it has the potential to affect several availability zones at once.
This whole issue lasted approximately 3.5 hours, then it miraculously stopped. Somebody must have fixed a defective router. Twitter reports from other people experiencing the exact same issue revealed that the issue was seen as fixed for them at the very minute that it was fixed for us too.
This incident brought home a valuable point for me though: we needed more monitors than we had available. We were monitoring connectivity 1) within the data center, 2) within EC2, and 3) between our data center and EC2. However, we also needed to monitor 4) inbound connectivity into EC2 going from sources that were outside of our data center infrastructure. Only by triangulating (for lack of a better term) our monitoring in this manner would we be sure which network path was to blame. Note that we already had Pingdom set up to monitor various URLs within our site, but like I said, the front-end stuff wasn't affected too much by that particular issue that night.
So...the next day we started up a small Rackspace cloud server in Chicago, and a small Linode VPS in Fremont, California, and we added them to our Nagios installation. We run the same exact checks from these servers into EC2 that we run from our data center into EC2. This makes network issues faster to troubleshoot, although unfortunately not easier to solve -- because we could be depending on a 3rd party to solve them.
I guess a bigger point to make, other than ABM/Always Be Monitoring, is OYA/Own Your Availability (I didn't come up with this, I personally first saw it mentioned by the @fastip guys). To me, what this means is to deploy your infrastructure across multiple providers (data centers/clouds) so that you don't have a single point of failure at the provider level. This is obviously easier said than done....but we're working on it as far as our infrastructure goes.
Wednesday, March 16, 2011
What I like and don't like to see in a technical presentation
What I like to see:
- Live demo of the technology/tool/process you are describing (or at least a screencast)
- Lessons learned -- the most interesting ones are the failures
- If you're presenting something you created:
- compare and contrast it with existing solutions
- convince me you're not suffering from the NIH syndrome
- convince me your creation was born out of necessity, ideally from issues you needed to solve in production
- Hard data (charts/dashboards)
- Balance between being too shallow and going too deep when covering your topic
- keep in mind both the HOW and the WHY of the topic
- Going above and beyond the information I can obtain with a simple Google search for that topic
- Pointers to any tools/resources you reference (GitHub pages preferred)
What I don't like to see:
- Cute slides with images and only a couple of words (unless you provide generous slide notes in some form)
- Humor is fine, but not if it's all there is
- Hand-waving / chest-pounding
- Vaporware
- No knowledge of existing solutions with established communities
- you're telling me you're smarter than everybody else in the room but you're not backing up that assertion
- Simple usage examples that I can also get via Google searches
- Abandoning the WHY for the HOW
- Abandoning the HOW for the WHY
Monday, March 14, 2011
Deployment and hosting open space at PyCon
One of the most interesting events for me this year at PyCon was an Open Space session organized by Nate Aune on deployment, hosting and configuration management. The session was very well attended, and it included representatives of a large range of companies. Here are some of them, if memory serves well: Disqus, NASA, Opscode, DjangoZoom, Eucalyptus, ep.io, Gondor, Whiskey Media ... and many more that I wish I could remember (if you were there and want to add anything, please leave a comment here).
Here are some things my tired brain remembers from the discussions we had:
All in all, there were some very interesting discussions that showed that pretty much everybody is struggling with similar issues. There is no silver bullet, but there are some tools and approaches that can help make your life easier in this area. My impression is that the field of automated deployments and configuration management, even though changing fast, is also maturing fast, with a handful of tools dominating the space. It's an exciting space to play in!
Here are some things my tired brain remembers from the discussions we had:
- everybody seems to be using virtualenv when deploying their Python applications
- everybody seems to be using Fabric in one way or another to push changes to remote nodes
- the participants seemed to be split almost equally between Puppet and Chef for provisioning
- the more disciplined of the companies (ep.io for example) use Puppet/Chef both for provisioning and application deployment and configuration (ep.io still uses Fabric for stopping/starting services on remote nodes for example)
- other companies (including us at Evite) use Chef/Puppet for automated provisioning of the OS + pre-requisite packages, then use Fabric to push the deployment of the application because they prefer the synchronous aspect of a push approach
- upgrading database schemas is hard; many people only do additive changes (NoSQL makes this easier, and as far as relational databases go, PostgreSQL makes it easier than MySQL )
- many people struggle with how best to bundle their application with other types of files, such as haproxy or nginx configurations
- at Evite we face the same issue, and we came up with the notion of a bundle, a directory structure that contains the virtualenv of the application, the configuration files for the application, and all the other configuration files for programs that interact with our application -- haproxy, nginx, supervisord for example
- when we do a deploy, we check out a bundle via a revision tag, then we push the bundle to a given app server
- some people prefer to take the OS package approach here, and bundle all the above types of files in an rpm or deb package
- Noah Kantrowitz has released 2 Chef-related Python tools that I was not aware of: PyChef (a Python client that knows how to query a Chef server) and commis (a Python implementation of a Chef server, with the goal of being less complicated to install than its Ruby counterpart)
- LittleChef was mentioned as a way to run Chef Solo on a remote node via fabric, thus giving you the control of a 'push' method combined with the advantage of using community cookbooks already published for Chef
- I had to leave towards the end of the meeting, when people started to discuss the hosting aspect, so I don't have a lot to add here -- but it is interesting to me to see quite a few companies that have Platform-as-a-Service (PaaS) offerings for Python hosting: DjangoZoom, ep.io, Gondor (ep.io can host any WSGI application, while the DjangoZoom and Gondor are focused on Django)
All in all, there were some very interesting discussions that showed that pretty much everybody is struggling with similar issues. There is no silver bullet, but there are some tools and approaches that can help make your life easier in this area. My impression is that the field of automated deployments and configuration management, even though changing fast, is also maturing fast, with a handful of tools dominating the space. It's an exciting space to play in!
Tuesday, March 08, 2011
Monitoring is for ops what testing is for dev
Devops. It's the new buzzword. Go to any tech conference these days and you're sure to find an expert panel on the 'what' and 'why' of devops. These panels tend to be light on the 'how', because that's where the rubber meets the road. I tried to give a step-by-step description of how you can become a Ninja Rockstar Internet Samurai devops in my blog post on 'How to whip your infrastructure into shape'.
Here I just want to say that I am struck by the parallels that exist between the activities of developer testing and operations monitoring. It's not a new idea by any means, but it's been growing on me recently.
Test-infected vs. monitoring-infected
Good developers are test-infected. It doesn't matter too much whether they write tests before or after writing their code -- what matters is that they do write those tests as soon as possible, and that they don't consider their code 'done' until it has a comprehensive suite of tests. And of course test-infected developers are addicted to watching those dots in the output of their favorite test runner.
Good ops engineers are monitoring-infected. They don't consider their infrastructure build-out 'done' until it has a comprehensive suite of monitoring checks, notifications and alerting rules, and also one or more dashboard-type systems that help them visualize the status of the resources in the infrastructure.
Adding tests vs. adding monitoring checks
Whenever a bug is found, a good developer will add a unit test for it. It serves as a proof that the bug is now fixed, and also as a regression test for that bug.
Whenever something unexpectedly breaks within the systems infrastructure, a good ops engineer will add a monitoring check for it, and if possible a graph showing metrics related to the resource that broke. This ensures that alerts will go out in a timely manner next time things break, and that correlations can be made by looking at the metrics graphs for the various resources involved.
Ignoring broken tests vs. ignoring monitoring alerts
When a test starts failing, you can either fix it so that the bar goes green, or you can ignore it. Similarly, if a monitoring alert goes off, you can either fix the underlying issue, or you can ignore it by telling yourself it's not really critical.
The problem with ignoring broken tests and monitoring alerts is that this attitude leads slowly but surely to the Broken Window Syndrome. You train yourself to ignore issues that sooner or later will become critical (it's a matter of when, not if).
A good developer will make sure there are no broken tests in their Continuous Integration system, and a good ops engineer will make sure all alerts are accounted for and the underlying issues fixed.
Improving test coverage vs. improving monitoring coverage
Although 100% test coverage is not sufficient for your code to be bug-free, still, having something around 80-90% code coverage is a good measure that you as a developer are disciplined in writing those tests. This makes you sleep better at night and gives you pride in producing quality code.
For ops engineers, sleeping better at night is definitely directly proportional to the quantity and quality of the monitors that are in place for their infrastructure. The more monitors, the better the chances that issues are caught early and fixed before they escalate into the dreaded 2 AM pager alert.
Measure and graph everything
The more dashboards you have as a devops, the better insight you have into how your infrastructure behaves, from both a code and an operational point of view. I am inspired in this area by the work that's done at Etsy, where they are graphing every interesting metric they can think of (see their 'Measure Anything, Measure Everything' blog post).
As a developer, you want to see your code coverage graphs showing decent values, close to that mythical 100%. As an ops engineer, you want to see uptime graphs that are close to the mythical 5 9's.
But maybe even more importantly, you want insight into metrics that tie directly into your business. At Evite, processing messages and sending email reliably is our bread and butter, so we track those processes closely and we have dashboards for metrics related to them. Spikes, either up or down, are investigated quickly.
Here are some examples of the dashboards we have. For now these use homegrown data collection tools and the Google Visualization API, but we're looking into using Graphite soon.
Outgoing email messages in the last hour (spiking at close to 100 messages/second):
 Size of various queues we use to process messages (using a homegrown queuing mechanism):
Size of various queues we use to process messages (using a homegrown queuing mechanism):

Percentage of errors across some of our servers:

Associated with these metrics we have Nagios alerts that fire when certain thresholds are being met. This combination allows our devops team to sleep better at night.
Here I just want to say that I am struck by the parallels that exist between the activities of developer testing and operations monitoring. It's not a new idea by any means, but it's been growing on me recently.
Test-infected vs. monitoring-infected
Good developers are test-infected. It doesn't matter too much whether they write tests before or after writing their code -- what matters is that they do write those tests as soon as possible, and that they don't consider their code 'done' until it has a comprehensive suite of tests. And of course test-infected developers are addicted to watching those dots in the output of their favorite test runner.
Good ops engineers are monitoring-infected. They don't consider their infrastructure build-out 'done' until it has a comprehensive suite of monitoring checks, notifications and alerting rules, and also one or more dashboard-type systems that help them visualize the status of the resources in the infrastructure.
Adding tests vs. adding monitoring checks
Whenever a bug is found, a good developer will add a unit test for it. It serves as a proof that the bug is now fixed, and also as a regression test for that bug.
Whenever something unexpectedly breaks within the systems infrastructure, a good ops engineer will add a monitoring check for it, and if possible a graph showing metrics related to the resource that broke. This ensures that alerts will go out in a timely manner next time things break, and that correlations can be made by looking at the metrics graphs for the various resources involved.
Ignoring broken tests vs. ignoring monitoring alerts
When a test starts failing, you can either fix it so that the bar goes green, or you can ignore it. Similarly, if a monitoring alert goes off, you can either fix the underlying issue, or you can ignore it by telling yourself it's not really critical.
The problem with ignoring broken tests and monitoring alerts is that this attitude leads slowly but surely to the Broken Window Syndrome. You train yourself to ignore issues that sooner or later will become critical (it's a matter of when, not if).
A good developer will make sure there are no broken tests in their Continuous Integration system, and a good ops engineer will make sure all alerts are accounted for and the underlying issues fixed.
Improving test coverage vs. improving monitoring coverage
Although 100% test coverage is not sufficient for your code to be bug-free, still, having something around 80-90% code coverage is a good measure that you as a developer are disciplined in writing those tests. This makes you sleep better at night and gives you pride in producing quality code.
For ops engineers, sleeping better at night is definitely directly proportional to the quantity and quality of the monitors that are in place for their infrastructure. The more monitors, the better the chances that issues are caught early and fixed before they escalate into the dreaded 2 AM pager alert.
Measure and graph everything
The more dashboards you have as a devops, the better insight you have into how your infrastructure behaves, from both a code and an operational point of view. I am inspired in this area by the work that's done at Etsy, where they are graphing every interesting metric they can think of (see their 'Measure Anything, Measure Everything' blog post).
As a developer, you want to see your code coverage graphs showing decent values, close to that mythical 100%. As an ops engineer, you want to see uptime graphs that are close to the mythical 5 9's.
But maybe even more importantly, you want insight into metrics that tie directly into your business. At Evite, processing messages and sending email reliably is our bread and butter, so we track those processes closely and we have dashboards for metrics related to them. Spikes, either up or down, are investigated quickly.
Here are some examples of the dashboards we have. For now these use homegrown data collection tools and the Google Visualization API, but we're looking into using Graphite soon.
Outgoing email messages in the last hour (spiking at close to 100 messages/second):


Percentage of errors across some of our servers:
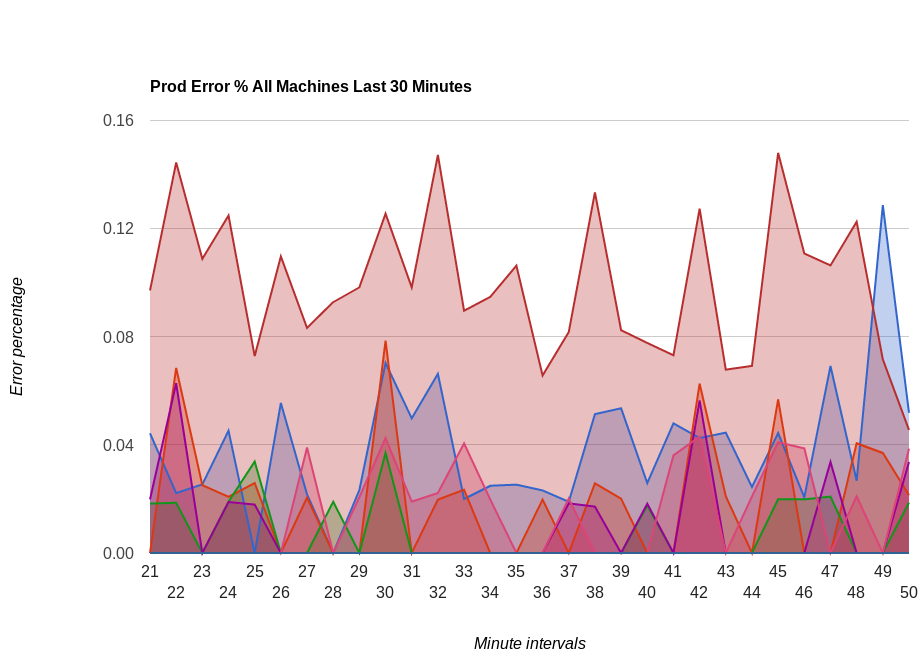
Associated with these metrics we have Nagios alerts that fire when certain thresholds are being met. This combination allows our devops team to sleep better at night.
Subscribe to:
Posts (Atom)