First of all, just a bit of theory. If you want to expose your application running on Kubernetes to the outside world, you have several choices.
One choice you have is to expose the pods running your application via a Service of type NodePort or LoadBalancer. If you run your service as a NodePort, Kubernetes will allocate a random high port on every node in the cluster, and it will proxy traffic to that port to your service. Services of type LoadBalancer are only supported if you run your Kubernetes cluster using certain specific cloud providers such as AWS and GCE. In this case, the cloud provider will create a specific load balancer resource, for example an Elastic Load Balancer in AWS, which will then forward traffic to the pods comprising your service. Either way, the load balancing you get by exposing a service is fairly crude, at the TCP layer and using a round-robin algorithm.
A better choice for exposing your Kubernetes application is to use Ingress resources together with Ingress Controllers. An ingress resource is a fancy name for a set of layer 7 load balancing rules, as you might be familiar with if you use HAProxy or Pound as a software load balancer. An Ingress Controller is a piece of software that actually implements those rules by watching the Kubernetes API for requests to Ingress resources. Here is a fragment from the Ingress Controller documentation on GitHub:
What is an Ingress Controller?
An Ingress Controller is a daemon, deployed as a Kubernetes Pod, that watches the ApiServer's /ingresses endpoint for updates to the Ingress resource. Its job is to satisfy requests for ingress.
Writing an Ingress Controller
Writing an Ingress controller is simple. By way of example, the nginx controller does the following:
- Poll until apiserver reports a new Ingress
- Write the nginx config file based on a go text/template
- Reload nginx
While nginx is the only software currently included in the Kubernetes source code as an Ingress Controller, I wanted to experiment with a full-fledged HTTP reverse proxy such as Traefik. I should add from the beginning that only nginx offers the TLS feature of Ingress resources. Traefik can terminate SSL of course, and I'll show how you can do that, but it is outside of the Ingress resource spec.
I've also been looking at Helm, the Kubernetes package manager, and I noticed that Traefik is one of the 'stable' packages (or Charts as they are called) currently offered by Helm, so I went the Helm route in order to install Traefik. In the following instructions I will assume that you are already running a Kubernetes cluster in AWS and that your local kubectl environment is configured to talk to that cluster.
Install Helm
This is pretty easy. Follow the instructions on GitHub to download or install a binary for your OS.
Initialize Helm
Run helm init in order to install the server component of Helm, called tiller, which will be run as a Kubernetes Deployment in the kube-system namespace of your cluster.
Get the Traefik Helm chart from GitHub
I git cloned the entire kubernetes/charts repo, then copied the traefik directory locally under my own source code repo which contains the rest of the yaml files for my Kubernetes resource manifests.
# git clone https://github.com/kubernetes/charts.git helmcharts
# cp -r helmcharts/stable/traefik traefik-helm-chart
For more details on Helm charts and templates, I recommend this linux.com article.
I copied the dashboard-ingress.yaml template file from the Traefik chart and customized it so as to refer to my application's web service, which is running in a Kubernetes namespace called tenant1.
The variables referenced in the template above are defined in the values.yaml file in the Helm chart. I started with the variables in the values.yaml file that came with the Traefik chart and added my own customizations:
Create tenant1.dev.mydomain.com and tenant1-lb.dev.mydomain.com as DNS CNAME records pointing to a5be275d8b65c11e685a402e9ec69178-91587212.us-west-2.elb.amazonaws.com.
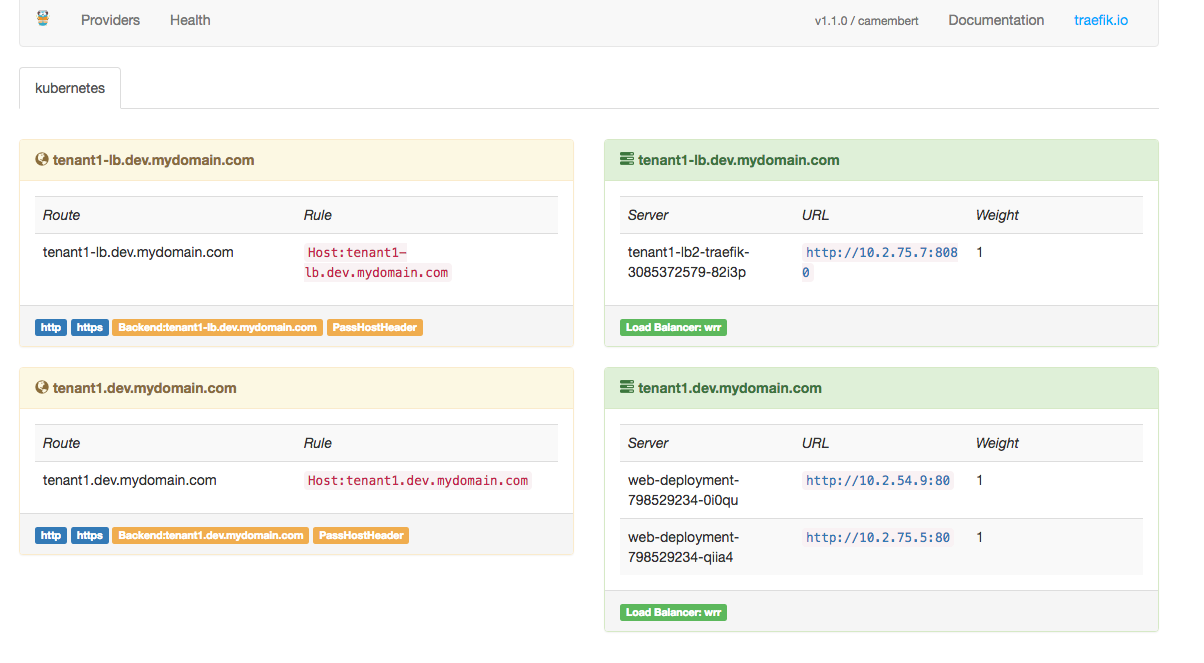
Now, if you hit http://tenant1-lb.dev.mydomain.com you should see the Traefik dashboard showing the frontends on the left and the backends on the right:
Other helm commands
# cd traefik-helm-chart/templates
# cp dashboard-ingress.yaml web-ingress.yaml
# cat web-ingress.yaml
{{- if .Values.tenant1.enabled }}
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
namespace: {{ .Values.tenant1.namespace }}
name: {{ template "fullname" . }}-web-ingress
labels:
app: {{ template "fullname" . }}
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
release: "{{ .Release.Name }}"
heritage: "{{ .Release.Service }}"
spec:
rules:
- host: {{ .Values.tenant1.domain }}
http:
paths:
- path: /
backend:
serviceName: {{ .Values.tenant1.serviceName }}
servicePort: {{ .Values.tenant1.servicePort }}
{{- end }}
The variables referenced in the template above are defined in the values.yaml file in the Helm chart. I started with the variables in the values.yaml file that came with the Traefik chart and added my own customizations:
# vi traefik-helm-chart/values.yaml
ssl:
enabled: true
acme:
enabled: true
email: admin@mydomain.com
staging: false
# Save ACME certs to a persistent volume. WARNING: If you do not do this, you will re-request
# certs every time a pod (re-)starts and you WILL be rate limited!
persistence:
enabled: true
storageClass: kubernetes.io/aws-ebs
accessMode: ReadWriteOnce
size: 1Gi
dashboard:
enabled: true
domain: tenant1-lb.dev.mydomain.com
gzip:
enabled: false
tenant1:
enabled: true
namespace: tenant1
domain: tenant1.dev.mydomain.com
serviceName: web
servicePort: http
Note that I added a section called tenant1, where I defined the variables referenced in the web-ingress.yaml template above. I also enabled the ssl and acme sections, so that Traefik can automatically install SSL certificates from Let's Encrypt via the ACME protocol.
Install your customized Helm chart for Traefik
With these modifications done, I ran 'helm install' to actually deploy the various Kubernetes resources included in the Traefik chart.
I specified the directory containing my Traefik chart files (traefik-helm-chart) as the last argument passed to helm install:
# helm install --name tenant1-lb --namespace tenant1 traefik-helm-chart/
NAME: tenant1-lb
LAST DEPLOYED: Tue Nov 29 09:51:12 2016
NAMESPACE: tenant1
STATUS: DEPLOYED
RESOURCES:
==> extensions/Ingress
NAME HOSTS ADDRESS PORTS AGE
tenant1-lb-traefik-web-ingress tenant1.dev.mydomain.com 80 1s
tenant1-lb-traefik-dashboard tenant1-lb.dev.mydomain.com 80 0s
==> v1/PersistentVolumeClaim
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
tenant1-lb-traefik-acme Pending 0s
==> v1/Secret
NAME TYPE DATA AGE
tenant1-lb-traefik-default-cert Opaque 2 1s
==> v1/ConfigMap
NAME DATA AGE
tenant1-lb-traefik 1 1s
==> v1/Service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tenant1-lb-traefik-dashboard 10.3.0.15 <none> 80/TCP 1s
tenant1-lb-traefik 10.3.0.215 <pending> 80/TCP,443/TCP 1s
==> extensions/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
tenant1-lb-traefik 1 1 1 0 1s
NOTES:
1. Get Traefik's load balancer IP/hostname:
NOTE: It may take a few minutes for this to become available.
You can watch the status by running:
$ kubectl get svc tenant1-lb-traefik --namespace tenant1 -w
Once 'EXTERNAL-IP' is no longer '<pending>':
$ kubectl describe svc tenant1-lb-traefik --namespace tenant1 | grep Ingress | awk '{print $3}'
2. Configure DNS records corresponding to Kubernetes ingress resources to point to the load balancer IP/hostname found in step 1
At this point you should see two Ingress resources, one for the Traefik dashboard and on for the custom web ingress resource:
# kubectl --namespace tenant1 get ingress
NAME HOSTS ADDRESS PORTS AGE
tenant1-lb-traefik-dashboard tenant1-lb.dev.mydomain.com 80 50s
tenant1-lb-traefik-web-ingress tenant1.dev.mydomain.com 80 51s
As per the Helm notes above (shown as part of the output of helm install), run this command to figure out the CNAME of the AWS ELB created by Kubernetes during the creation of the tenant1-lb-traefik service of type LoadBalancer:
# kubectl describe svc tenant1-lb-traefik --namespace tenant1 | grep Ingress | awk '{print $3}'
a5be275d8b65c11e685a402e9ec69178-91587212.us-west-2.elb.amazonaws.com
Now, if you hit http://tenant1-lb.dev.mydomain.com you should see the Traefik dashboard showing the frontends on the left and the backends on the right:
If you hit http://tenant1.dev.mydomain.com you should see your web service in action.
You can also inspect the logs of the tenant1-lb-traefik pod to see what's going on under the covers when Traefik is launched and to verify that the Let's Encrypt SSL certificates were properly downloaded via ACME:
# kubectl --namespace tenant1 logs tenant1-lb-traefik-3710322105-o2887
time="2016-11-29T00:03:51Z" level=info msg="Traefik version v1.1.0 built on 2016-11-18_09:20:46AM"
time="2016-11-29T00:03:51Z" level=info msg="Using TOML configuration file /config/traefik.toml"
time="2016-11-29T00:03:51Z" level=info msg="Preparing server http &{Network: Address::80 TLS:<nil> Redirect:<nil> Auth:<nil> Compress:false}"
time="2016-11-29T00:03:51Z" level=info msg="Preparing server https &{Network: Address::443 TLS:0xc4201b1800 Redirect:<nil> Auth:<nil> Compress:false}"
time="2016-11-29T00:03:51Z" level=info msg="Starting server on :80"
time="2016-11-29T00:03:58Z" level=info msg="Loading ACME Account..."
time="2016-11-29T00:03:59Z" level=info msg="Loaded ACME config from store /acme/acme.json"
time="2016-11-29T00:04:01Z" level=info msg="Starting provider *main.WebProvider {\"Address\":\":8080\",\"CertFile\":\"\",\"KeyFile\":\"\",\"ReadOnly\":false,\"Auth\":null}"
time="2016-11-29T00:04:01Z" level=info msg="Starting provider *provider.Kubernetes {\"Watch\":true,\"Filename\":\"\",\"Constraints\":[],\"Endpoint\":\"\",\"DisablePassHostHeaders\":false,\"Namespaces\":null,\"LabelSelector\":\"\"}"
time="2016-11-29T00:04:01Z" level=info msg="Retrieving ACME certificates..."
time="2016-11-29T00:04:01Z" level=info msg="Retrieved ACME certificates"
time="2016-11-29T00:04:01Z" level=info msg="Starting server on :443"
time="2016-11-29T00:04:01Z" level=info msg="Server configuration reloaded on :80"
time="2016-11-29T00:04:01Z" level=info msg="Server configuration reloaded on :443"
To get an even better warm and fuzzy feeling about the SSL certificates installed via ACME, you can run this command against the live endpoint tenant1.dev.mydomain.com:
# echo | openssl s_client -showcerts -servername tenant1.dev.mydomain.com -connect tenant1.dev.mydomain.com:443 2>/dev/null
CONNECTED(00000003)
---
Certificate chain
0 s:/CN=tenant1.dev.mydomain.com
i:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
-----BEGIN CERTIFICATE-----
MIIGEDCCBPigAwIBAgISAwNwBNVU7ZHlRtPxBBOPPVXkMA0GCSqGSIb3DQEBCwUA
-----END CERTIFICATE-----
1 s:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
i:/O=Digital Signature Trust Co./CN=DST Root CA X3
-----BEGIN CERTIFICATE-----
uM2VcGfl96S8TihRzZvoroed6ti6WqEBmtzw3Wodatg+VyOeph4EYpr/1wXKtx8/
KOqkqm57TH2H3eDJAkSnh6/DNFu0Qg==
-----END CERTIFICATE-----
---
Server certificate
subject=/CN=tenant1.dev.mydomain.com
issuer=/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
---
No client certificate CA names sent
---
SSL handshake has read 3009 bytes and written 713 bytes
---
New, TLSv1/SSLv3, Cipher is AES128-SHA
Server public key is 4096 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : AES128-SHA
Start Time: 1480456552
Timeout : 300 (sec)
Verify return code: 0 (ok)
etc.
You can list the Helm releases that are currently running (a Helm release is a particular versioned instance of a Helm chart) with helm list:
# helm list
NAME REVISION UPDATED STATUS CHART
tenant1-lb 1 Tue Nov 29 10:13:47 2016 DEPLOYED traefik-1.1.0-a
If you change any files or values in a Helm chart, you can apply the changes by means of the 'helm upgrade' command:
# helm upgrade tenant1-lb traefik-helm-chart
You can see the status of a release with helm status:
# helm status tenant1-lb
LAST DEPLOYED: Tue Nov 29 10:13:47 2016
NAMESPACE: tenant1
STATUS: DEPLOYED
RESOURCES:
==> v1/Service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tenant1-lb-traefik 10.3.0.76 a92601b47b65f... 80/TCP,443/TCP 35m
tenant1-lb-traefik-dashboard 10.3.0.36 <none> 80/TCP 35m
==> extensions/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
tenant1-lb-traefik 1 1 1 1 35m
==> extensions/Ingress
NAME HOSTS ADDRESS PORTS AGE
tenant1-lb-traefik-web-ingress tenant1.dev.mydomain.com 80 35m
tenant1-lb-traefik-dashboard tenant1-lb.dev.mydomain.com 80 35m
==> v1/PersistentVolumeClaim
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
tenant1-lb-traefik-acme Bound pvc-927df794-b65f-11e6-85a4-02e9ec69178b 1Gi RWO 35m
==> v1/Secret
NAME TYPE DATA AGE
tenant1-lb-traefik-default-cert Opaque 2 35m
==> v1/ConfigMap
NAME DATA AGE
tenant1-lb-traefik 1 35m

